链路追踪
随着业务发展,后端服务单元不断增加,导致一个前端请求需要诸多后端服务参与,这也使得如果请求出现问题变慢难以定位原因。此时就需要链路追踪系统。
分布式链路追踪系统会跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
一般地,一个分布式链路追踪系统分为三个部分:数据收集,数据存储和数据展示。
spring cloud sleuth
spring cloud sleuth 是 spring cloud 的分布式链路追踪解决方案的实现。
基本术语
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
Span: 基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
Trace: 一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
Annotation: 用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束。在sleuth使用了Brave以后,已不需要使用这些特定事件来让zipkin理解是client或server,事件的开始以及结束。但为了学习的目的,仍然将这些行为标注出来。这些注解包括以下:
- cs: Client Sent,客户端发送一个请求,这个注解描述了这个Span的开始
- sr: Server Received,服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
- ss: Server Sent,服务端发送响应,该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
- cr: Client Received,客户端接收响应,此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
下图展示了工作图:

zipkin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
实践
搭建zipkin server
新建zipkin server项目,zipkin 可以使用 http,rabbitmq 等方式来进行数据交换,这里采用rabbitmq的方式。在持久化方面可使用 mysql,elasticsearch 等方式,这里采用elasticsearch。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>lyyljs.cloud</groupId>
<artifactId>zipkinserver</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>zipkinserver</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.RELEASE</spring-cloud.version>
<zipkin.version>2.12.8</zipkin.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>${zipkin.version}</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>${zipkin.version}</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmq</artifactId>
<version>${zipkin.version}</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch</artifactId>
<version>${zipkin.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
|
zipkin server 采用了 armeria 作为web容器,所以这里需要将默认的web容器监听端口关闭,并对配置 armeria。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| server:
port: -1
register:
port1: 8000
port2: 8001
port3: 8002
armeria:
ports:
- port: 9411
protocol: HTTP
zipkin:
storage:
StorageComponent: elasticsearch
type: elasticsearch
elasticsearch:
hosts: localhost:9200
collector:
rabbitmq:
addresses: localhost:5672
username: guest
password: guest
queue: zipkin
spring:
application:
name: spring-cloud-zipkin-server
eureka:
instance:
hostname: localhost
client:
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.register.port1}/eureka/
|
1
2
3
4
| @SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
public class ZipkinserverApplication {
|
访问 http://localhost:9411/zipkin 进入可视化页面。
为producer添加追踪组件
1
2
3
4
5
6
7
8
| <dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| spring:
application:
name: spring-cloud-producer
zipkin:
#base-url: http://localhost:9411
sender:
type: rabbit
sleuth:
messaging:
rabbit:
enabled: true
sampler:
#应采样的请求的概率。 例如。 应该对1.0 - 100%的请求进行抽样。 精度仅为整数(即不支持0.1%的迹线)。
probability: 1.0
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
|
为consumer添加追踪组件
同producer相同
1
2
3
4
5
6
7
8
| <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| spring:
application:
name: spring-cloud-consumer
zipkin:
#base-url: http://localhost:9411
sender:
type: rabbit
sleuth:
messaging:
rabbit:
enabled: true
sampler:
#应采样的请求的概率。 例如。 应该对1.0 - 100%的请求进行抽样。 精度仅为整数(即不支持0.1%的迹线)。
probability: 1.0
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
|
测试
访问 http://localhost:9001/hello/lyyljs, 然后在zipkin server可视化页面查看
路径追踪:
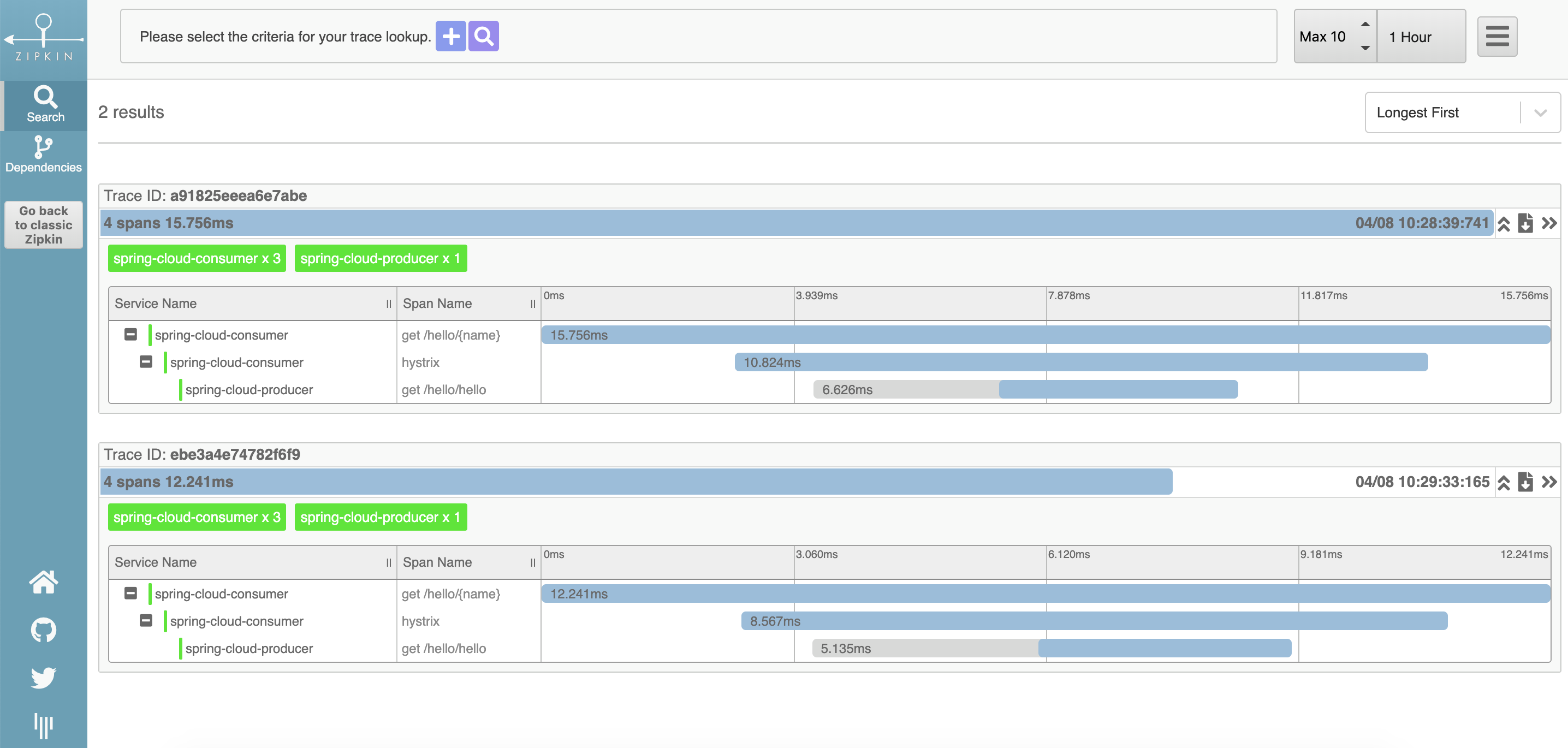
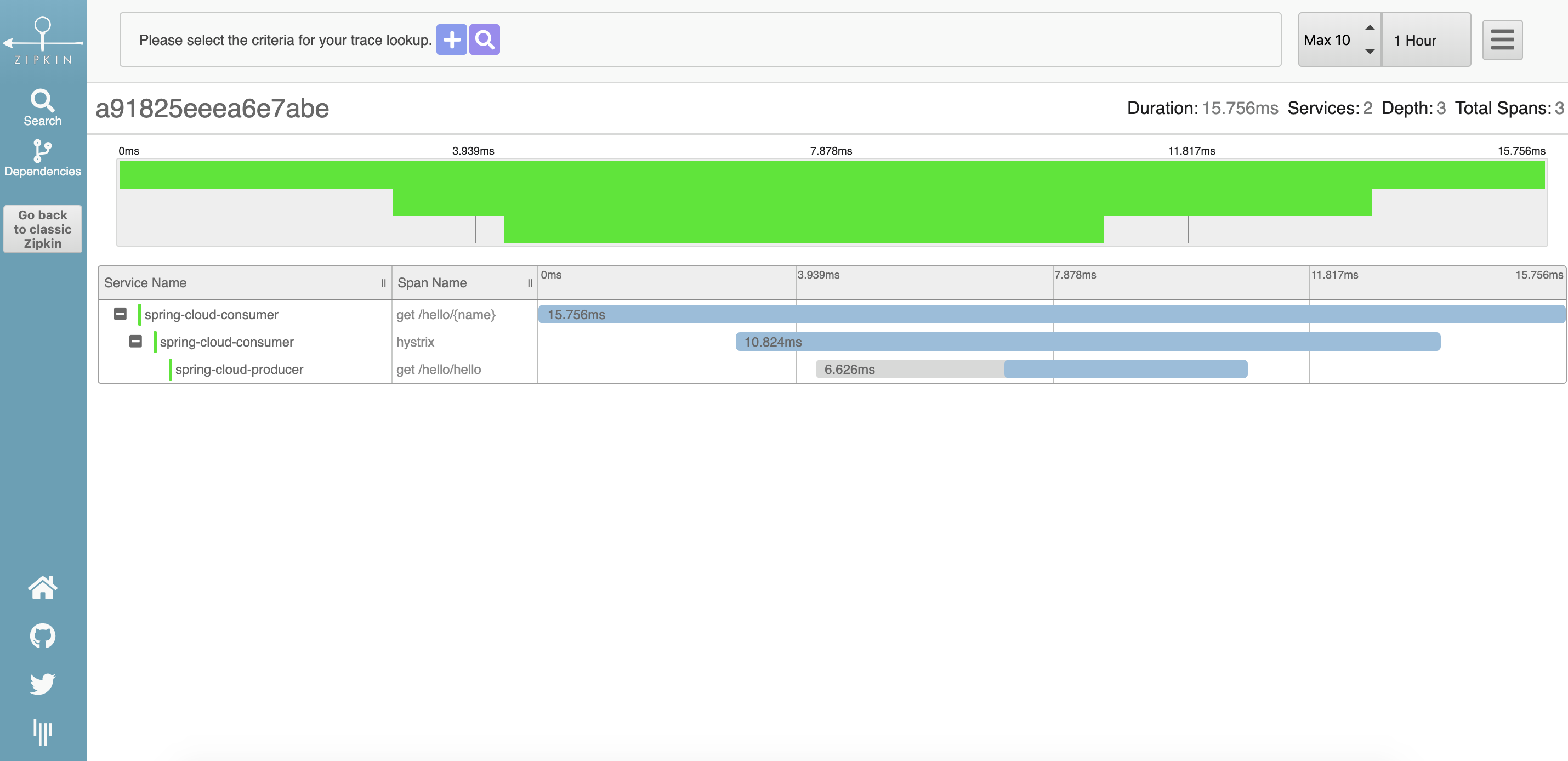
可点击进入trace详情
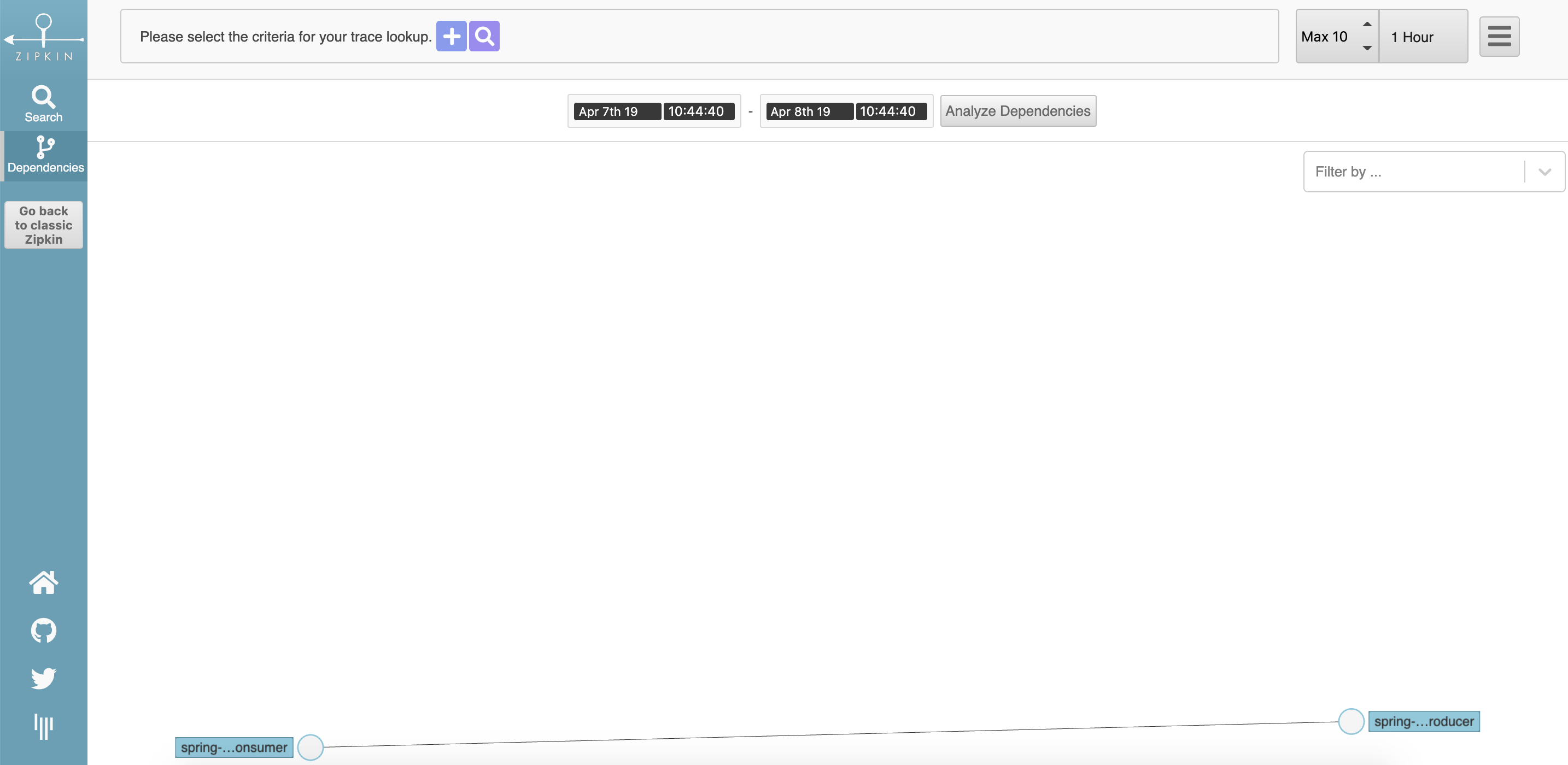
依赖分析:
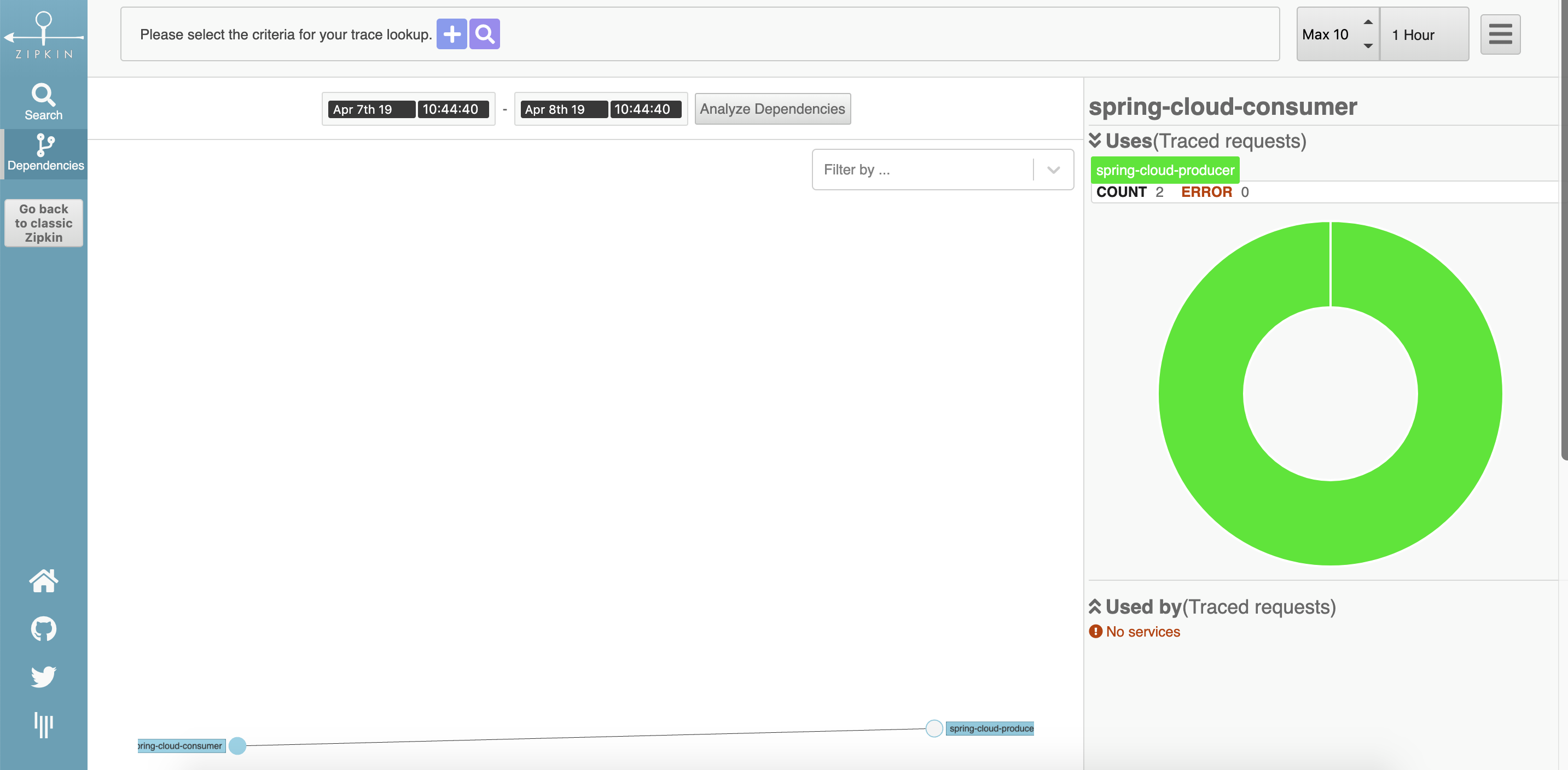
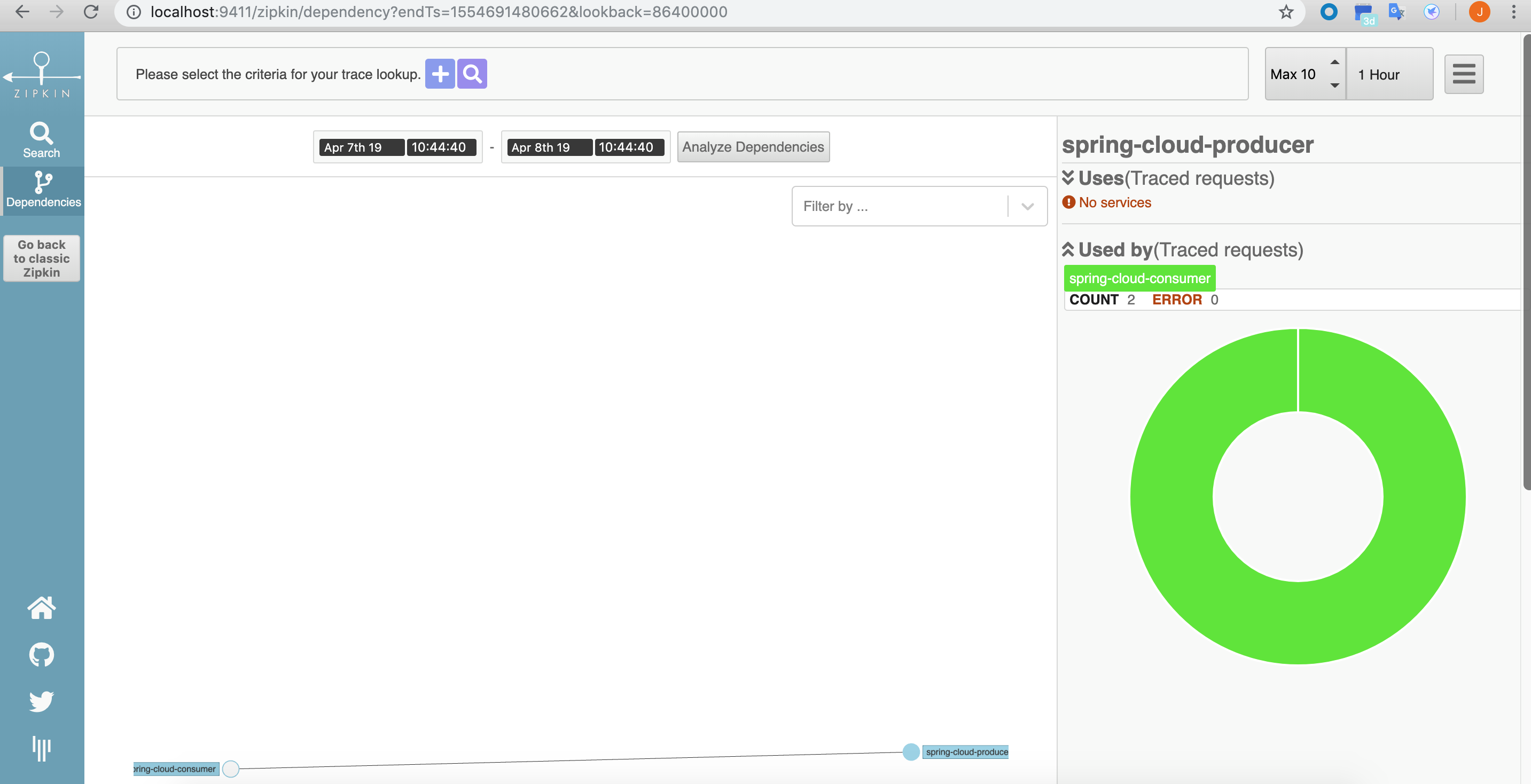
可点击服务查看详情:
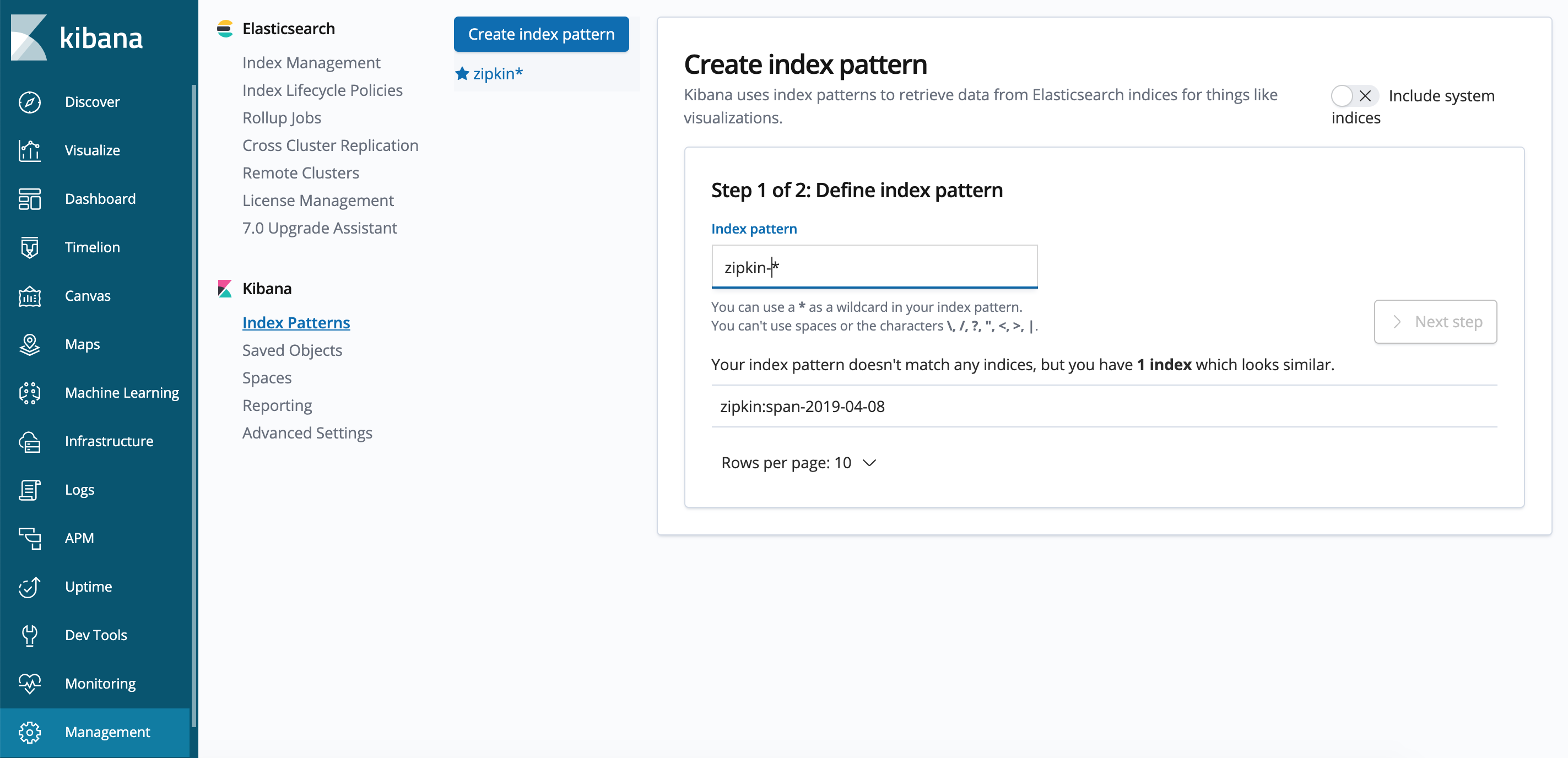
在kibana建立index:
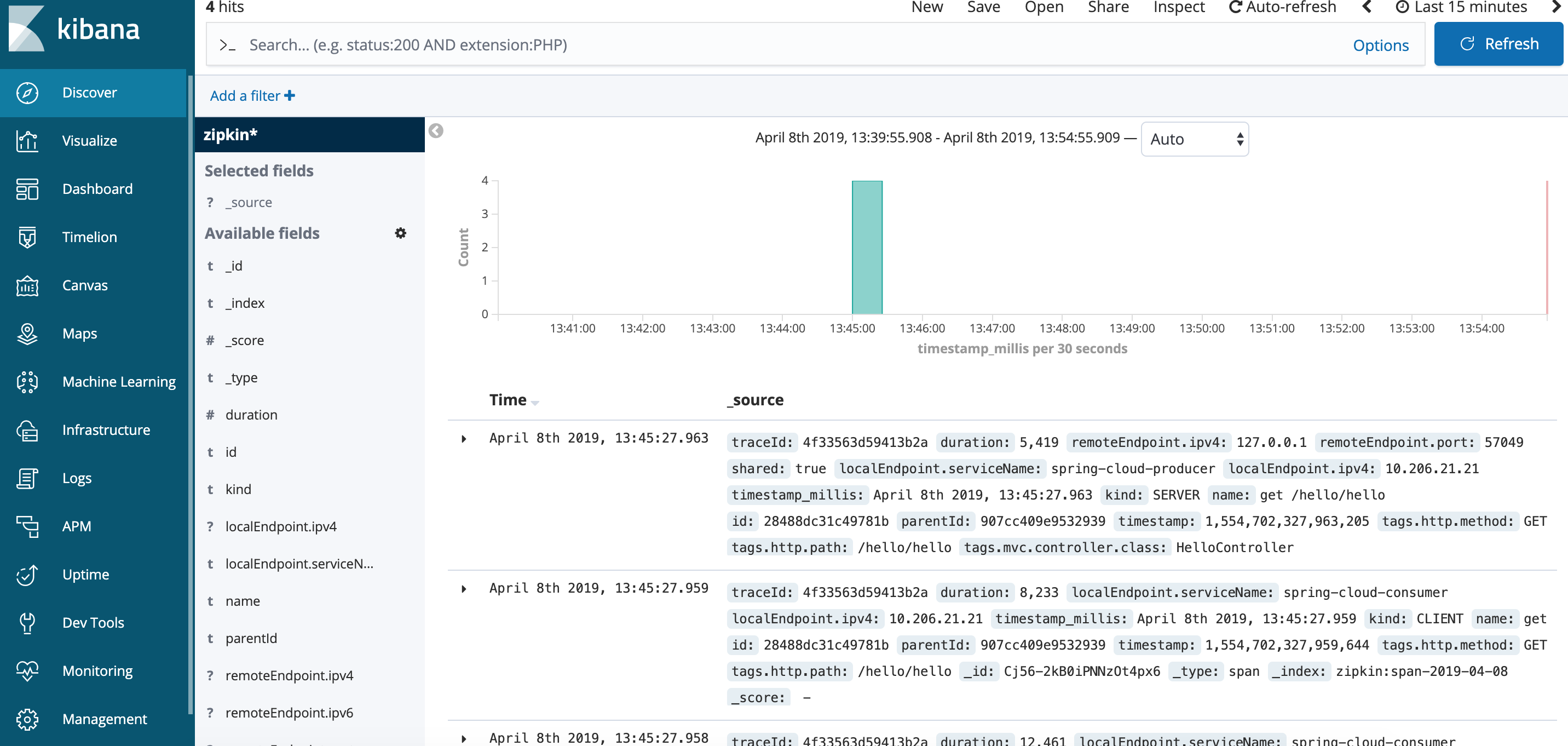
在kibana查看elasticsearch的数据:
参考